Superhuman Powers for Superhero Developers
Reducing technical debt by optimizing developer tools, enhancing the software development lifecycle with reproducibility, leveraging AI, navigating RAG and more


In 2018, Stripe released a report estimating that improving the efficiency of software engineering has the potential to raise global GDP by $3T over the next ten years. At the time of the report, there were 18M estimated developers globally while today we have ~27M and growing. Since 2018, numerous technological advancements have been achieved to realize those benefits. What follows delves into the realm of developer productivity and experience, streamlining the software development lifecycle (SDLC), the renaissance solution (AI), and the risks associated with achieving incremental gains.
Developers are force-multipliers, with their productivity correlating directly with technological advancement and efficiency. But as an engineering organization grows, maintaining developer productivity is hard. It is inevitable that individual engineer productivity drops with scale as the codebase grows. Technical debt - a metaphor introduced by Ward Cunningham in 1992 - is defined as long term costs incurred by moving quickly in software engineering. Today, technical debt is the top frustration at work for professional developers according to 62% of developers as features and functionality are sacrificed for suboptimal performance to push a project forward. As with bank loans, there could be reasons to “take on technical debt”, but ultimately it needs to be paid down otherwise it will compound over time. Reducing dependencies, refactoring code, and improving testing among other factors helps pay down the debt. This takes place across the SDLC.
The SDLC is where engineering teams take code from developer environments (where code is composed) to application runtime (putting infrastructure into place to execute) and deploy it to production (executing code where it is used by the end user). Once in production, code will be further observed, debugged and monitored. The tooling required is built and maintained by teams to ensure stability and reliability. However, the best tooling in the world will struggle to make up for regularly losing time in debugging environments. An instance would be an application that worked in the development environment, but then broke in staging and production, thus requiring teams to go through an end-to-end process to troubleshoot where the error lies and what caused it. Here is an example of code going through the DevOps SDLC.

To elaborate, software is built within complex environments and requirements that include various tools, libraries, frameworks and configurations. Each project has its own set of dependencies that must be managed, adding to the complexity. To create an environment, you need to use a package manager, install system dependencies, integrate 3-4 necessary tools, possibly set up a Virtual Machine (VM), and containerize everything to run both locally and in the cloud. Additionally, you must keep track of which instances (development, testing, staging, or production) are active for which engineers, and have the capability to roll back version history and access source control code for editing. Onboarding new engineers can also be time-consuming, as documentation (like readmes) can quickly become outdated due to software and requirement updates, and engineers might be using different operating systems and architectures. Therefore, the requirements to simply get up and running to build software can be overwhelming.
The golden path to production includes consistency across tooling from dev environments, staging and production, while achieving stability, availability and security. Sounds easy right? Even with all the innovative new individual tools built (thank you Cloud Native Landscape), piecing it together is difficult. Managing growing workloads in a large organization, across multiple platforms and in various programming languages, introduces a significant level of complexity. In fact, ranking #2 and #3 in most common frustrations by developers is complexity of tech stack for build/deployment, with #4 being reliability of tools/systems used in work. As such, over 60% of leaders are using Continuous Integration / Continuous Deployment (CI/CD) pipelines, allowing more engineers to actively participate in the development process. Modern teams like platform engineering enable more collaborative DevOps experience.
As discussed, streamlining the SDLC could be a difficult task with various patchwork needed. Spinning up containers and virtual environments to set up consistent build frameworks or managing disparate dependencies across projects, platforms and CI workflows complemented by navigating specific package managers to get the latest packages; it adds up! Not only that but any inconsistency in taking an environment from a local dev station, to build, causes headaches with debugging.
What are the options?
One area is around core infrastructure and a concept called reproducibility. At Flox, we’re looking to reduce the complexity of modern software development and operations throughout the SDLC. We are a package manager and virtual environment today, with a build system for software and storehouse coming soon. We empower developers to build instantly, easily creating reproducible, cross-platform development or application environments, all without containers. Our easy to use package manager allows for multiple, isolated environments, all with a distinct combination of packages that are portable and can work with any language or toolchain. Environments can be easily switched between and shared with co-workers, regardless of platform used. Flox offers the world’s largest catalog of software, built on top of Nixpkgs, including over 1M unique package/version combinations - comprising both fresh software released just yesterday, and legacy versions of software packages released years ago.
The secret sauce is that Flox is built on top of Nix. Nix is a cross-platform package manager that enables you to use declarative methods (like providing a detailed blueprint) to build software deterministically (like following an exact recipe every time); allowing for reliability and reproducibility when developing software. It is the 7th largest open-source project on Github with over 100K+ packages available. It is also famously challenging to learn - however my friend Alex Mackenzie does a great job of explaining it in his Nix Primer. It is complex and multi-layered with documentation being incomplete and sometimes difficult to understand. Flox gives the best bits of Nix - including access to its open-source software - without the complexity. Over time we are excited to provide proactive analysis (analyzing package requirements and dependencies to eliminate dependency conflicts) for packages and environments, social sharing and collaboration of environments, and a storehouse fleet manager that centralizes supply chain for software. This allows for a single source of management to have enterprises work from the same collection of packages with ability of instant upgrades, rollbacks and security solutions.
Flox enables organizations to operate more efficiently by overcoming the isolating tools and roadblocks that hinder reproducibility and portability across the SDLC, from local development to CI and production deployment. This includes getting to building as fast as possible; security benefits with consistent, repeatable software builds; reduced onboarding time for new developers and centralized control over the software supply chain. We aim to solve for less debugging, less vulnerabilities and more consistency.
The next topic to cover is AI. AI has already unlocked considerable engineering efficiencies and directly addresses tech debt. The ability to enhance and automate engineering with AI will touch every aspect of the SDLC from code generation to deployment. In the latest 2024 Stack Overflow survey, 81% of respondents say productivity is the biggest benefit that developers identify for AI tools, followed by speed up learning (62.4%) and greater efficiency (58.5%). Specifically, the majority of AI usage in the engineering workflow is oriented around writing code (code generation + autocomplete), debugging (rewrites + refactoring + edits), code quality, search documentation and testing. While writing code maintains its position as the highest usage of AI, both debugging (56.7%) and documenting code (40.1%) usage has surpassed its 2023 levels resulting in a 16% and 17% increase, respectively. Important to note that testing code, which was the most “desired” usage of AI from the 2023 survey, increased in usage by 14% this year.

Today, code assist is the Gen AI application with the most widespread adoption and clear ROI. As demonstrated above, devs spend the majority of their time writing code while the rest of the time goes into reading specs, docs, code reviews, meetings, co-worker troubleshooting, debugging preexisting code, provisioning environments, incidents, and more. Specifically, when it comes to copilots in the SDLC, 72% of leaders are looking to reduce time spent on routine coding tasks. Two observed trends have been AI co-pilots that enhance existing workflows alongside engineers (Github Co-Pilot, Tabnine, Codeium) and AI agents replacing workflows end-to-end (Devin, SWE Agent, Factory, CodeGen and more), unlocking a new level of productivity. GitHub Copilot has become the most widely adopted AI-powered developer tool. Within two years since General Availability, more than 77K organizations have adopted Copilot (180% YoY growth). Copilot accounted for 40%+ of GitHub’s revenue growth this year and the new workspace product affects productivity across plan, build, test, debug and deploy cycle.

The opportunity to integrate AI is large and consulting firms seem to be capitalizing on the trend. Accenture is on track to make $2.4B annualized from Gen AI; IBM has secured >$1B in sales commitments related to Gen AI consulting; ~40% of McKinsey’s business this year will be Gen AI related and 20% of BCG’s revenue will come from the same source. In a 2023 Survey of the Large Effects of AI on Economic Growth by Goldman, it was noted that ¼ of current work tasks could be automated by AI in the US and Europe.

The top three shares of industry employment exposed to automation by AI were Office and Admin Support (46%), Legal (44%) and Architecture and Engineering (37%). For the purposes of our dive into the power of the developer, we will continue to focus on engineering.
We’ve established that AI is good. But with great power in AI building, comes great specialty required to know how to build.
To build with AI, you need the experience and knowledge to not only unlock work with AI in your existing workflow, but to build with it, you’d need the necessary tools at your disposal. As technology has evolved, engineers are required to learn various tech stacks, gain access to tools and knowledge across languages to work in a specific domain. Consider the analytics, data, and AI fields and the software expertise required to operate in these areas.

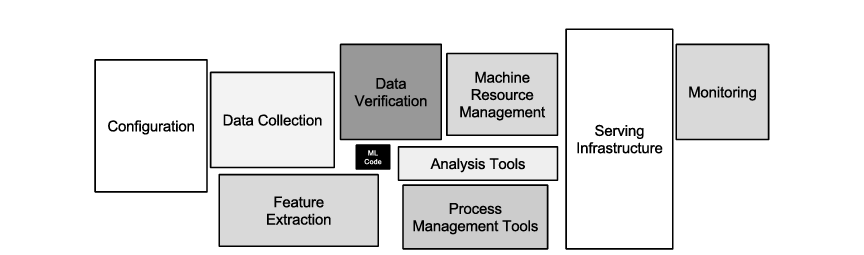
While Machine Learning offers powerful toolkits for building useful complex prediction systems quickly, building these systems is difficult. In a 2015 paper on Technical Debt in ML Systems, the following architecture shows the end to end requirements of building these systems. Only a small fraction (as denoted by the black box in the diagram below) of real-world ML systems is composed of ML code. The surrounding infra that is required to build these systems is vast and complex, and oftentimes incurs massive ongoing maintenance costs in building and maintaining these services.
Two weeks ago Meta released Llama 3.1 405B, an open-source model trained on over 15T tokens using more than 16,000 H100 GPUs. How do I get started fine-tuning Llama or running the latest diffusion models? Before jumping into the latest version, I need to update and modernize my local development environment. To start, we pull up a terminal / shell / command line (Zsh, Tmux, htop etc) and get going. In order to experiment with python code, we can jump into an Integrated Development Environment (IDE) for coding. Some examples of IDE’s below and their popularity from this survey amongst developers include:

VS Code in particular has gained a lot of popularity within the Python Community over the past few years particularly for serious development on a library or repository. Jupyter Notebooks are easy to set up, visualize and have been a go-to source for AI/ML tutorials. The next requirement is inference and computation. With sufficient RAM, running sophisticated models for inference on your laptop becomes straightforward, enabling AI development. In fact, Hugging Face has a memory calculator to understand how much RAM is needed to train and perform large model inference locally.
On the other hand if I want to train a larger model, it’ll require GPU availability. GPUs are necessary to train AI models but access to GPUs is limited due to capacity constraints from manufacturers. As a result, I’d have to build and manage my own GPU inference cluster or hire specialized talent to do so. However, there are various options for AI Infra providers that abstract complexity to bring AI capabilities to products. For example, Modal, Baseten and Together are cloud compete offerings that simplify getting AI/ML models running in the cloud. They produce a serverless offering that scales to hundreds of GPUs and back down to zero very quickly. The premise is that you can scale up learnings to run/train via this offering, get results, iterate and improve the AI/ML dev cycle.
Now that I have my terminal, IDE, and inference/compute in place, we can get started by accessing AI/ML libraries and packages. Hugging Face has become the de facto library for open source AI/ML models, along with libraries and tools for easily working with them. It offers pre-trained models from the model hub allowing for fine-tuning it as well. Let’s take the Transformers library for example. Using the library I can pull from the model hub for PyTorch, TensorFlow and JAX. Transformers provides APIs and tools to download these trained models, around NLP, computer vision, and multimodal abilities. Diffusers on the other hand provide pretrained models for generating images, audio and 3D structures.
One more item to discuss - CUDA (compute unified device architecture), is a computing platform and programming model developed by NVIDIA. CUDA allows developers to use Nvidia GPUs for processing. To activate CUDA, we’ll need the necessary environment variables, paths and libraries required for CUDA to function (packages, latest version of Python, etc). This usually results in spinning up separate containers cross platform to make work which could be frustrating.
Our team at Flox have recently released the FLAIM environment - overcoming the challenges of varying architectures and GPU acceleration issues, regardless of operating system or toolchain. FLAIM simplifies the need of manually searching for the proper requirements by enabling GPU-accelerated environments directly on local systems using Flox, ensuring reproducibility without relying on containers. If you activate a Flox remote environment (FLAIM for example), it attempts to enable GPU acceleration and then you will automatically have access to a few key packages to run the models. These include diffusers, transformers, PyTorch, accelerate and others. Below is what running FLAIM looks like with key packages installed.
Now that we have our stack set up, we can go from experimentation to deployment.
When developing in AI, the goal is to go from experimentation to deployment (AI in production). For enterprises, putting forward secure environments into production for employees and customers is incredibly important. For performance and security purposes, the models must run in environments that are flexible and scalable. Over the years, many companies have faced challenges with data silos, complex deployment workflows and governance, when translating ML experimentation to production. Today, the narrative has started to shift. According to the State of Data and AI by Databricks, 1,018% more models were registered for production this year than last year and for the first time, the growth of models registered outpaced the growth of experiments logged. Organizations have realized measurable gains in putting ML models into production. That being said, adoption is still early as Morgan Stanley’s latest CIO survey showed that 30% of big company CIOs don’t expect to deploy anything until 2026.
The exercise below conducted in a Bain survey demonstrates that enterprise LLM adoption is still in development via pilots and experiments and less on production (deployments). Specifically deployments are more apparent in software code development and customer service when it comes to internal productivity.
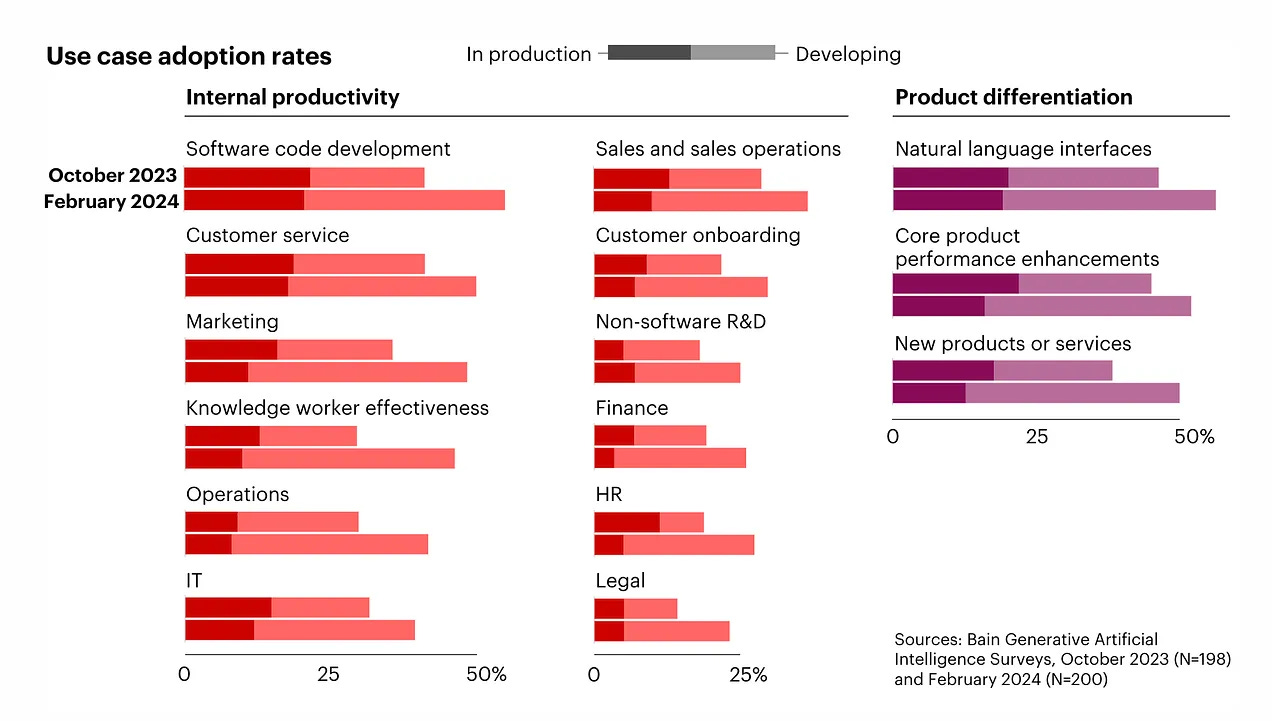
Adoption of enterprise Gen AI accelerates as CIOs put use cases into production. However, an enterprises’ knowledge base is dynamic and constantly updating and models (LLMs) must be accurate in critical use cases. As such, enterprises need to understand how to deploy large models and work with LLMs. Enter: retrieval mechanisms to access all potential data (internal and application level data), gain permission to the data, extract the data for the best output to be delivered and more. As it stands, data is dispersed across an organization within applications, spreadsheets and files, with access being difficult. Without retrieval, a model is limited to the knowledge it’s been trained on which severely inhibits the enterprise use case.
Breaking down the RAG stack.
Retrieval Augmented Generation (RAG) has a large role to play in going from experimentation to production. RAG is a GenAI application pattern that finds data and documents relevant to a question or task and provides them as context for the LLM to give more accurate responses. Specifically, LLMs possess limited domain-specific knowledge, so teams must implement knowledge augmentation techniques to create valuable experiences. RAG will be the key to enterprises deploying LLMs at scale, allowing for enterprise adoption of AI and keeping costs in check. Databricks found that 60% of LLM applications use some form of RAG. Glean is an example of an enterprise search tool to help organizations find information across various internal sources. When a query is made, Glean retrieves data by analyzing the context and intent, then presents concise and accurate results, making it easy for users to find information they need quickly.
Most teams would start with prompt level optimizations like RAG and move toward model-level optimizations such as routing or fine-tuning; all driven by performance, cost and latency. The latest evolution comes from using multiple models and route prompts to get to the most performant model for retrieval. The excitement from RAG comes from its stack of supplementary technologies across data retrieval (pre-processing, chunking, post-processing, etc) that will make it fundamental to putting use cases into production with reliability and enhanced performance. For the context of this article, we will focus on RAG as a way to incorporate proprietary, real-time data into LLMs without the costs and time requirements of fine-tuning or pre-training a model.
Breaking down the stack, how it looks like.

To begin, unstructured data needs to be extracted from various sources, but data extraction remains a significant challenge (data pipelines). Vector databases are then used to store the embeddings or vectors that represent the underlying text. These databases can be thought of as “supercharging” the in-app search experience by finding documents or records based on similarity to keywords in a query. With vector databases integrated, if we were to search for Q1 2023 metrics, it would identify the phrases and passages that fit our search within a given set of data, making its own inference. This is done in part by storing data in a vector embedding then classifying it, which Gen AI models can then consume and pull relevant info that is faster, accurate and complete. Specialized vendors include Pinecone, Weaviate, Chroma, Quadrant and more. With RAG, vector databases are used to train the underlying models on private data to generate more accurate outputs that are relevant to a company’s operations. Enterprises are aggressively pursuing this customization as the use of vector databases grew 377% in the last year.
Graph databases and operations follows - helping store graph structures that hold as the tissue between the underlying text (for storage and execution). Knowledge graphs are used to store and retrieve knowledge, or to interpret the logic of data located elsewhere, such as in a vector database. These graphs organize data into interconnected entities and relationships (as seen in a supply chain model here), creating a structure that ensures responses generated by RAG are accurate and contextually relevant. Comprising nodes and relationships, knowledge graphs represent individual data points as nodes, while relationships define their connections. Each node can have properties, offering additional context or attributes to the node. In a practical manner, knowledge graphs help unlock agentic workflows, allowing AI to pull nuanced context from an enterprises’ proprietary internal knowledge base (think the Q1 2023 metrics example, or entity specific information that is fragmented).
These powers unlock the ability to identify critical data for execution on important decisions / insights. Multi-agent frameworks like Crew AI and Autogen for example, focus on interactions between multiple autonomous agents to achieve complex goals. Orchestration frameworks that serve as abstraction layers when agent navigation is complex, such as Langchain and LlamaIndex, manage the workflow and integration of AI models to streamline development and deployment. Well known LLMs, including OpenAI, Llama, and Claude, form the foundation that RAG systems leverage to retrieve relevant information and generate accurate responses. Using all these systems points to a simple question. What is the ROI of RAG? The key value lies in the time saved when finding answers, significantly reducing the SLA required to complete the process. This efficiency translates into substantial savings, as it reduces the portion of employees' wages that would otherwise be spent on parsing information. Additionally, it reduces LLM compute costs since it eliminates the need to load all the data into the context window.
Taking it one step further, Galileo recently released the LLM Hallucination Index - evaluating 22 leading models across three RAG tasks, providing insights on performance, cost and verbosity to help teams choose optimal LLM for their use case. In this instance, adding additional context has emerged as a way to improve RAG performance. The tests were conducted on three scenarios: Short Context (less than 5k tokens, equivalent to RAG on a few pages), Medium Context (5k-25k tokens = book chapter), and Long Context (40k-100k tokens = book). The large takeaways include open source closing the gap for performance without cost of barriers, models performing particularly well with extended context lengths without losing quality or accuracy, smaller models can outperform larger models (Gemini 1.5 outperformed larger models), and Anthropic outperforming OpenAI. Synopsis on the overall winners below.

Below you’ll find an example of Short Context RAG where it seeks to identify the most efficient model for understanding contexts up to 5k tokens. Its primary goal is to detect any loss of information or reasoning capability within these contexts. This would be relevant for domain-specific knowledge. While the X-axis is evident around cost, the Y-axis is a measurement of closed-domain hallucination: where the model said things not provided in the context. If response is adherent to content - it has a value of 1 - only containing information given the context. If a response is not adherent, it’s likely to contain facts not included in context. In the case below, Claude 3.5 Sonnet won best closed source, Llama-3-70b-chat won best open source and Gemini 1.5 Flash won best affordable model.

I mentioned briefly the options of applying data retrieval vs owning + fine-tuning a model. What should a startup do? Should they rely on existing models (calling GPT/Claude or fine-tune a base model) or go through a capital-intensive process of building their own specific model? Could smaller models outperform larger base models? To what degree does a model need to be pre-trained on code to see improvement? Is there enough high quality code data to train on? Github copilot for example doesn’t have a model trained, but runs on smaller models and code fine-tuned GPT models. It is (hopefully now) evident that there are significant MLops efforts required to custom fine-tune models, which ultimately accrue technical debt. Data preparation for fine-tuning could be harder than fine-tuning itself. It is recommended that folks start with prompt engineering or basic RAG before considering fine-tuning; it is both cost effective and efficient and only when exhausted prompting, consider fine-tuning.
Where does that leave us? Optionality. Companies prefer to use a multi-model, open-source approach to decrease reliance on any single vendor, allowing for speed of change, avoiding lock-in, and staying up to date with most advanced model improvements. Smaller optimized models over larger models provide speed and cost savings with a preference for prompting and RAG techniques. In fact, 60% of enterprises adopt multiple models (and route prompts to the most performant model). Companies like Martian focus on model routing and eliminate single-model dependencies, offering controllability and cost savings.
Risks in AI.
While AI has promise to be the technological shift to allow us to unlock efficiencies within the tech debt we’ve accumulated, there are still risks involved. The biggest inhibiting factors are compute and storage, data and security while establishing AI specific guardrails. The current pace of progress requires ongoing innovation in hardware, otherwise society will be unable to scale model size due to limitations.
Compute and Storage
Much of the risk in AI today is being held by infrastructure providers and the cost for them to operate. The biggest storyline within AI has been the large-scale capex required on data centers to train and deliver AI models. How many more chips can be made? Where will the power come from? And most importantly, where is the ROI? Data centers are required to keep AI products running, and acquiring computers will continue to be a problem as it is expensive to do well. Expenditures are pointing towards AI hardware and data centers. In fact, the world’s largest tech companies are in an AI arms race with NVIDIA’s GPUs standing at the center. MSFT spent $19B in capex last quarter, up 80% YoY while guiding to estimates of spend being $56B for 2024, while Meta just guided towards a range of $37B-$40B for FY2024, updated from the prior range of a low bar being $35B. The rationale behind the spend is that it will be key to capture the opportunity of AI.
While investments seem like a big risk, the risk of not participating in this arms race is even greater. Google CEO, Sundar Pichai, on their last earnings call mentioned “The risk of under investing is dramatically greater than the risk of over-investing. Not investing to be at the frontier has more significant downsides”. At the same time, Meta’s CEO was asked by Bloomberg about the AI Bubble to which he responded in the same tone “I’d much rather over-invest and pay for that outcome than save money by developing more slowly.” In the latest earnings, Mark Zuckerberg when discussing his long-term outlook on AI investment, mentions “it’s hard to predict how this will trend multiple generations into the future.. I’d rather risk building capacity before it is needed rather than too long, given the long lead times for spinning up new inference projects.” A major focus for Meta is figuring out the right level of infra capacity to support training more advanced models. The amount of compute needed to train Llama 4 will likely be 10x more than Llama 3. The focus today is seemingly not on monetization. Meta CFO recently mentioned “We don’t expect our GenAI products to be a meaningful driver of revenue in ‘24, but we do expect that they’re going to open up new revenue opportunities over time that will enable us to generate a solid return on our investment.” Although OpenAI has built one of the fastest-growing businesses in history, It was just reported that OpenAI is estimated to lose $5B this year. This burn is caused primarily by its AI training and inference costs along with considerable staffing. However, investments like these are needed. Like governments did in the past, big tech companies are making high upfront infrastructure investments to spur innovations which are critical to AI’s long-term impact. We can think of it as a subsidy for the startups that are building on top of them, with big tech companies being the producers and startups as the consumers of compute. The arms race between MSFT, Meta and Google will enable scaling laws and lower pricing for everyone around them.
Data centers have become the most important asset and the future of innovation in AI is dependent on expanding capacity.
Training Data
As AI models become larger, faster and more ambitious in capabilities, they require more and more high-quality data to be trained on. The search for data comes down to crawling the web for new data (limited), creating synthetic data (tricky), licensing data (costly) or involving humans. Most of the data on the internet today is already trained on and we are running out of open training data. Data scarcity and abundance require a new means of production to fuel AI progress. Large companies are paying big amounts to acquire training data. OpenAI recently announced data licensing deals with Reddit, Stack Overflow and various publishers as original content presents crucial data training infrastructure for the next generation of models. Reddit for example is rumored to be a $60M annual contract which prices out many companies without large funding. This demonstrates the immense volume and value of internal enterprise data needed to fuel the next generation of AI models
Meta highlighted its use in training Llama 3.1 on synthetic data. The risk is if models are recursively trained on their own synthetic outputs. Synthetic data can create short lived improvements to model performance that over time start to degrade performance if all incremental data is synthetic data. Data limitations arise as most of the new data used to train language models will be augmented by an existing model in some way. Finding alternative ways to extract human data (Scale AI as an example or OpenAI using an outsourcing firm in Kenya to label data), although most prohibitive and expensive, will make for long term differentiation for players in this space.
Security
As enterprises go from experimentation to production of use cases in AI, more investment will be needed to direct into AI Governance, Risk and Compliance (GRC) to mitigate downstream risks. This will ensure models comply with regional and international regulations across data privacy and other issues. In a survey led by Insight, 32% of respondents shared that investment in AI GRC is a top priority in 2024 while 28% of respondents say that the biggest barrier for deploying GenAI applications is security of proprietary data. In general, no AI will be deployed at scale in enterprise without AI security. Large enterprises will require secure deployments of AI models and secure AI applications. If every developer will be using a Gen AI solution to develop faster, there will be a need to embed and automate security.
There is a lot more to be said about security in general, perhaps for another post!
Closing
Achieving software engineering efficiency is crucial for reducing technical debt, a persistent issue that hampers long-term success. Developers, equipped with the right tools and processes, have the potential to be superhuman in their productivity, driving innovation and economic growth. By streamlining the SDLC and leveraging solutions like AI, reproducibility and comprehensive CI/CD pipelines, engineering teams can mitigate the compounding effects of technical debt. Not only does this enhance developer experience, but also ensures stability, security and scalability across projects. This enables developers to create impactful solutions and transform technical debt from a burden into a manageable piece of software development. In closing, developers truly become the unsung heroes of the tech world, propelling us toward a future of outsized technological advancement.
Thank you for reading along. If you spend time in this space, I’d love to continue learning and dive deeper.